0x00 关于Spark
Hadoop通过解决了大数据的可靠存储和处理1。
- HDFS,在普通PC组成的集群上提供高可靠的文件存储。
- MapReduce,通过简单的Mapper和Reducer的抽象提供一个编程模型,并发处理数据。
但是MapReduce抽象程度低,复杂度高,缺乏整体性,缺乏表达力。
而Apache Spark是一个新兴的大数据处理引擎,主要特点是提供了一个集群的分布式内存抽象,以支持需要工作集的应用。这个抽象就是RDD。
Spark的优势不仅体现在性能提升上的,Spark框架为批处理(Spark Core),交互式(Spark SQL),流式(Spark Streaming),机器学习(MLlib),图计算(GraphX)提供一个统一的数据处理平台,这相对于使用Hadoop有很大优势。

Spark提供了Python编程API,可以利用其接口编写Python程序并提交给Spark集群运行。本文分析和部分翻译了官方编程指南2中Python相关的内容。
0x01 编程第一步:初始化
Spark提供的Python编程接口为pyspark。程序中,首先要创建一个SparkContext对象,用来访问Spark集群。创建SparkContext之前,可以先创建一个SparkConf对象,用来设置相关配置。如:
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName(appName).setMaster(master)
sc = SparkContext(conf=conf)
或直接创建SparkContext:
sc = SparkContext(appName='test')
0x02 Resilient Distributed Datasets (RDDs)
Spark解决方案都是围绕着resilient distributed dataset (RDD)进行的。RDD是一个可以并行操作的具有容错的数据集合。有两种方式创建RDDs, 一是将主程序中的已有数据集合parallelizing化,二是引入一个外部存储上的数据集,比如HDFS、文件系统、HBase等等
2.1 Parallelized Collections
使用SparkContext的parallelize()方法,可以将程序中的可迭代对象、数据集合等转换为Spark的并行集合(Parallelized Collections)。 集合中的各个元素被拷贝形成一个分布式数据集,从而可以并行操作。如:
data = [1, 2, 3, 4, 5]
distData = sc.parallelize(data)
2.2 External Datasets
PySpark可以从任何Hadoop支持的数据源(如:本地文件系统, HDFS, Cassandra, HBase, Amazon S3等等)创建一个分布式数据集。Spark支持文本文件、SequenceFiles、以及其他Hadoop输入格式。
文本文件的RDDs,可以使用SparkContext的textFile()方法创建,该方法接收一个URI输入(本地文件路径, hdfs://, s3n://等等),并逐行读取内容。
>>> distFile = sc.textFile("data.txt")
创建之后,可以对distFile进行数据集操作
distFile.map(lambda s: len(s)).reduce(lambda a, b: a + b)
map(line) 对传入的元素逐个进行操作。reduce(function,list) 接受一个函数和一个list,对list的每一列反复调用该函数,并返回最终结果。
- 数据源如果为本地文件系统路径,则必须保证worker节点可以访问到这个路径,如:将文件拷贝到各个节点、或者使用网络共享的文件系统路径。
- Spark中所有基于文件的输入方法(包括textFile),均支持文件目录、压缩包、或者通配符等等形式。如:
textFile("/my/directory"),textFile("/my/directory/*.txt")和textFile("/my/directory/*.gz") - textFile()函数可选的第二个参数,可用来指定文件的分区数。默认情况下,Spark为每块文件(128M)创建一个分区,也可以手工指定更多的分区。
除此之外,Spark Python API 还支持其他数据格式:
- SparkContext.wholeTextFiles 可以用来读取一个包含很多小文本文件的目录,返回每个小文件键值对(文件名、内容)。与textFile相反,textFile会将每个文件的每一行作为一个记录返回。
- RDD.saveAsPickleFile 和 SparkContext.pickleFile 支持将RDD 保存为由pickled Python 对象组成的简单格式。
- SequenceFile 和 Hadoop Input/Output 格式
2.3 RDD Operations
RDDs 支持两种类型的操作:
transformations,对一个数据集进行一定的计算后创建一个新数据集。actions,在数据集上运行一系列计算后返回一个值给主节点。
如, map()就是一个 transformation。它接受一个自定义函数,并将原数据集中的每个元素经过该函数计算后返回为新的RDDs。另一方面,
reduce()会将每一个元素通过指定函数重复聚集计算后,返回最终结果给主程序(另外还有一个并行的reduceByKey会返回一个分布式数据集)。
所有transformations都是lazy的,并不会马上计算。如果数据集map计算后会马上在reduce中使用,只会返回reduce的结果,而不是map运算后庞大的数据集。
默认情况下,每次操作一个转换后的RDD都需要重新计算,可以使用persist或者cache方法来将各个元素保存在内存中,从而更快的访问。
lines = sc.textFile("data.txt") # lines仅仅是该文件的指针,在操作之前并不会将内容加载到内存中
lineLengths = lines.map(lambda s: len(s)) # 进行map转换,由于lazy机制,lineLengths也不会马上计算
totalLength = lineLengths.reduce(lambda a, b: a + b) # reduce是一个action,在这一步spark才会将计算任务分发到每一个工作节点
lineLengths.persist() # 如果我们后面还会用到lineLengths,可以在reduce前调用persist,在第一次计算后将它持久化。
2.3.1 Passing Functions to Spark
Spark’s API非常依赖于函数传递,建议通过三种方式
- Lambda expressions
- 局部defs
- modules的顶层函数
当时传递一个类内的函数时,函数中引用到对象的成员变量的话,计算时会将整个对象传递给集群。可以将成员变量赋值给函数内的局部变量来避免这种问题。
https://stackoverflow.com/questions/28569374/spark-returning-pickle-error-cannot-lookup-attribute
Currently, PySpark can not support pickle a class object in current script ( ‘main’), the workaround could be put the implementation of the class into a separate module, then use “bin/spark-submit –py-files xxx.py” in deploy it
2.3.2 Understanding closures
在集群环境下,Spark程序的变量和函数的生命周期和作用域较为难理解。对作用域之外变量的RDD操作经常会产生问题。
counter = 0
rdd = sc.parallelize(data)
# Wrong: Don't do this!!
def increment_counter(x):
global counter
counter += x
rdd.foreach(increment_counter)
print("Counter value: ", counter)
Spark将RDD操作分成一个个子任务,分发给各个执行节点。执行之前,Spark会计算任务的闭包。闭包就是那些为了RDD操作计算而必须要对执行节点可见的变量和函数。比如上述代码中的foreach。闭包会序列化之后发送给执行节点。发送给执行节点的闭包内的变量都是副本,都不再是执行节点上原来的变量了。为了适用这些场景,需要适用 Accumulator,Accumulators是在任务被分割到不同的执行节点的场景下的,安全更新变量的机制。
闭包,有点像是循环或者本地定义的函数,不应该去操作全局状态。如果需要聚合全局数据时,请使用Accumulator。
2.3.3 Printing elements of an RDD
有时候需要打印出RDD的每一个元素,用rdd.foreach(println) 或者 rdd.map(println)的话,打印的标准输出会在各个执行节点上,而不会显示在主节点上。如果要在主节点上打印的话,需要使用collect() 先将RDD拉取到主节点上,这可能会耗尽主节点的内存,所以如果是要查看一部分数据,可以使用take(),比如:rdd.take(100).foreach(println)。
2.3.4 Working with Key-Value Pairs
大多数Spark上的RDD操作包含了各种类型对象,但是有一部分操作只能应用于Key-Value的RDDs。比如 reduceByKey()。计算一个文本中,每一行出现了多少次:
lines = sc.textFile("data.txt")
pairs = lines.map(lambda s: (s, 1))
counts = pairs.reduceByKey(lambda a, b: a + b)
2.3.5 Transformations
Transformations详细列表。Spark支持的一些常用Transformation函数如:
map(func)
将传入每一个元素经过函数func处理后,返回一个新的分布式数据集
reduce(func)
将每个元素聚合计算后最终返回一个值
reduceByKey(func, [numTasks])
reduceByKey就是对元素为KV键值对的RDD中Key相同的元素的Value经过函数func聚合操作。Key相同的多个元素的值被reduce为一个值,然后与原RDD中的Key组成一个新的KV对。
val a = sc.parallelize(List((1,2),(1,3),(3,4),(3,6)))
a.reduceByKey((x,y) => x + y).collect
//结果 Array((1,5), (3,10))
//相同Key的Value进行累加
sortByKey([ascending], [numTasks])
When called on a dataset of (K, V) pairs where K implements Ordered, returns a dataset of (K, V) pairs sorted by keys in ascending or descending order, as specified in the boolean ascending argument.
sortBy(func,[ascending],[numPartitions])
func函数返回排序key,如 sortBy(lambda line: (line[0],line[1]))
更多排序: http://blog.csdn.net/jiangpeng59/article/details/52938465
2.3.6 Actions
下面是一下常用的Action函数:
reduce(func)
使用传入的函数:func 将数据集中的元素进行聚合操作,该函数接受两个值(上一个计算结果和后一个元素),返回一个值(聚合结果)。而且函数必须为可交换的(commutative)并且联想的(associative),从而可以正确的进行并行计算。
collect()
将数据集的所有元素返回给主节点。这个函数通常用在filter或者其他操作之后,用于返回一个较小的数据子集。
count()
返回数据集的元素个数。
take(n)
返回数据集中前n个元素组成的数组。first()返回第一个元素,与take(1)类似。
takeSample(withReplacement, num, [seed])
从数据集中随机挑选num个元素,组成一个样本数组并返回。使用或者不适用replacement,可选传入一个随机种子seed
countByKey()
对于(K, V)形式的RDD,返回(K, Int)形式的键值对,包含了每个键的元素个数。
foreach(func)
对数据集的每一个元素运行函数func。
2.3.7 Shuffle operations
Spark中的一些操作会触发shuffle事件,shuffle是Spark中一种重新分配数据的机制,因此它在不同分区之间不同分组。通常包括在不同执行节点和机器之间拷贝数据,从而使shuffle事件变得耗费较大并且很复杂。
background
我们可以通过reduceByKey操作来理解shuffle过程中发生了什么。reduceByKey操作将每个Key对应的所有值进行聚合操作,并最终返回一个结果,由每个Key和其对应的聚合结果组成一个个新的元组,最终生成一个新的RDD。而挑战在于一个Key的所有值并不一定都存在于同一个分区上,甚至不在一台机器上,但是他们必须协同来完成计算。
Spark中以便操作,数据通常不会跨分区分布。计算过程中,单个任务一般只操作单个分区。从而为了reduceByKey这单个reduce任务筹备数据,Spark需要执行一个all-to-all操作,它需要读取所有分区寻找所有Key对应的Value,然后将跨分区的Value集中起来计算每个Key聚合结果。这就是所谓的shuffle。
新shuffle的分区中的数据不是有序的,如果想要在shuffle之后得到一些可预知顺序的结果,可以通过以下方法:
mapPartitions来给每个用到的分区进行排序,比如:.sorted- 使用
repartitionAndSortWithinPartitions在重新分区的同时有效地进行分区排序 - 使用
sortBy进行全局的RDD排序
会引发shuffle的操作包括:重新分区操作,如repartition和coalesce;ByKey操作(除了计数类操作),比如 groupByKey 和 reduceByKey;join操作,比如 cogroup和join。
Performance Impact
Shuffle是一个耗资源的操作。在传输前需要内存数据来组织记录,所以某些shuffle操作会占用大量的堆内存。当数据量超过内存大小后,Spark会将这些表写入磁盘,同时会带来额外的磁盘I/O和垃圾回收。
Shuffle也会产生大量的中间文件。受Spark的垃圾回收机制影响,长时间运行的Spark任务会消耗大量的磁盘空间。临时存储路径由spark.local.dir 在Spark上下文进行配置。
有很多配置可以用来调整Shuffle的行为,可以参见Spark配置指南中的‘‘Shuffle Behavior’章节。Spark Configuration Guide
2.4 RDD Persistence
Spark一个重要的功能就是在内存中持久化(或缓存)persisting (or caching) 一个数据集。当你持久化RDD后,每个节点会存储它在内存中计算的任何分区,并在对该数据集的其他操作上重用这部分数据。这会使后续操作快十倍以上。
使用persist() 或者 cache()方法来缓存RDD。它会现在节点上计算,然后缓存在内存中。存储时容错的,如果哪一个分区的数据丢失了,它会自动重新计算该部分数据。
可传参控制存储级别(序列化后存入内存、磁盘等等): http://spark.apache.org/docs/latest/rdd-programming-guide.html#rdd-persistence
Remove Data
Spark会自动将老旧的数据移除掉,根据最不常使用的规则。使用RDD.unpersist()方法可以手动移除数据。
0x03 Shared Variables
正常来说,当一个函数传给Spark操作(比如map和reduce)时,它会在远程集群节点上被执行,而函数中的所有变量会复制成好几份。这些变量被复制到每个机器上,当远程节点向主节点反馈结果时,也不会更新这些变量。任务之间的读写共享变量变得很低效。然而Spark为两种通用场景提供了受限的共享变量:broadcast variables和accumulators。
3.1 Broadcast Variables
Broadcast variables允许程序员在每台机器上维持一个只读的缓存变量,而不是在每个任务中传输该变量的副本。比如:它们可以用来有效地给每个节点提供一个大的数据集副本。Spark也尝试使用更有效的广播算法分发broadcast变量,来减少通信消耗。
Spark的操作会通过阶段集合(Stages)来执行,被分布式的“shuffle”操作分离。在每个阶段(Stage),Spark会自动广播所有任务都需要的共同数据。这种方式广播的数据以序列化的形式缓存,并在任务运行之前反序列化。这也就表明,显示的创建broadcast variables仅在任务跨多阶段并且需要相同的数据时有用。或者当数据缓存为反序列化形式非常重要时才需要显示创建broadcat Variables。
通过调用SparkContext.broadcast(v)可以从变量v创建一个Broadcast variables。broadcast variables包装了v,可以通过调用value方法来访问它的值。
>>> broadcastVar = sc.broadcast([1, 2, 3])
<pyspark.broadcast.Broadcast object at 0x102789f10>
>>> broadcastVar.value
[1, 2, 3]
Bradcast variables创建之后,每个在集群上运行的函数都应该使用它而不是变量v,这样v就不会多次重复的传输到各个节点上。另外,在广播之后,为了保证每个节点获得了相同的broadcast variables的值,v变量不应该再修改。(e.g. if the variable is shipped to a new node later).
3.2 Accumulators
Accumulators是仅通过关联和交换操作来“added”的变量,因此可以有效的支持并行。可以用来实现计数器(在MapReduce中)或者求和。Spark原生支持数字类型的accumulators,程序员可以添加更多类型的支持。
作为一个用户,你可以创建命名的或者未命名的accumulators。如下图所示,对于修改了这个accumulator的stage,命名的accumulator会在web界面上显示。Spark在Tasks表格中显示了每个任务修改accumulator的值。
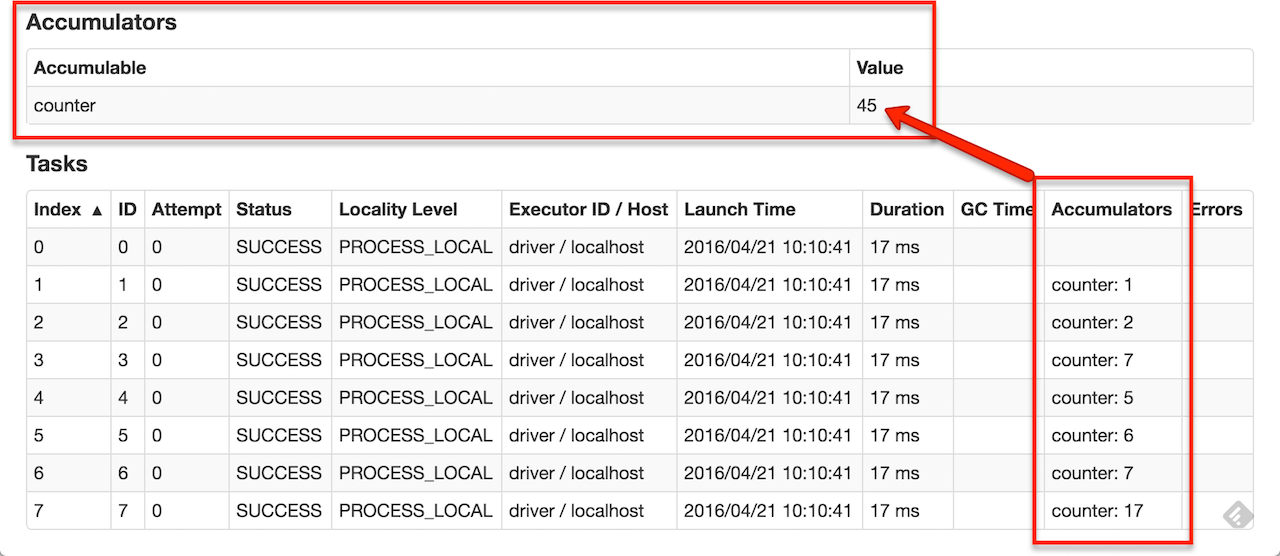
调用SparkContext.accumulator(v)可以从v创建一个accumulator。集群上运行的任务可以通过add方法或者+=操作符来进行加运算。但是并不能读取accumulator的值。只有主节点可以读取它的值,使用value方法。
>>> accum = sc.accumulator(0)
>>> accum
Accumulator<id=0, value=0>
>>> sc.parallelize([1, 2, 3, 4]).foreach(lambda x: accum.add(x))
...
10/09/29 18:41:08 INFO SparkContext: Tasks finished in 0.317106 s
>>> accum.value
10
上面的代码使用了accumulator内置支持的Int类型,程序员也可以通过定义AccumulatorParam子类来创建accumulator的其他类型。AccumulatorParam接口有两个方法: zero 为你的数据类型提供一个零值,addInPlace用来将两个值相加。